
Large-Scale Text Analysis of Industrial Policy
THE PROBLEM / CHALLENGE
Modern industrial and innovation policies are increasingly embedded in vast volumes of strategy documents, national reports, and policy papers. While these documents contain rich, actionable intelligence about government priorities and directions, they have traditionally been treated as narrative texts rather than quantitative data sources. Analysing them manually across dozens of countries and over multiple years is simply not feasible — the sheer scale of the task exceeds what any research team could accomplish with standard computing resources. Researchers face a fundamental bottleneck: thousands of policy documents exist, but no efficient, reproducible method has been available to extract comparable, structured signals from them at a cross-national scale.
The challenge was further compounded by the need for methodological rigor. Extracting meaningful policy signals — such as how much attention a given topic receives, or whether it is framed positively or negatively — requires applying Natural Language Processing (NLP) pipelines to tens of thousands of documents simultaneously. On a standard laptop or workstation, running such a complete analytical workflow would take several weeks, making iterative model development and large-scale cross-country comparison practically impossible.

SOLUTION
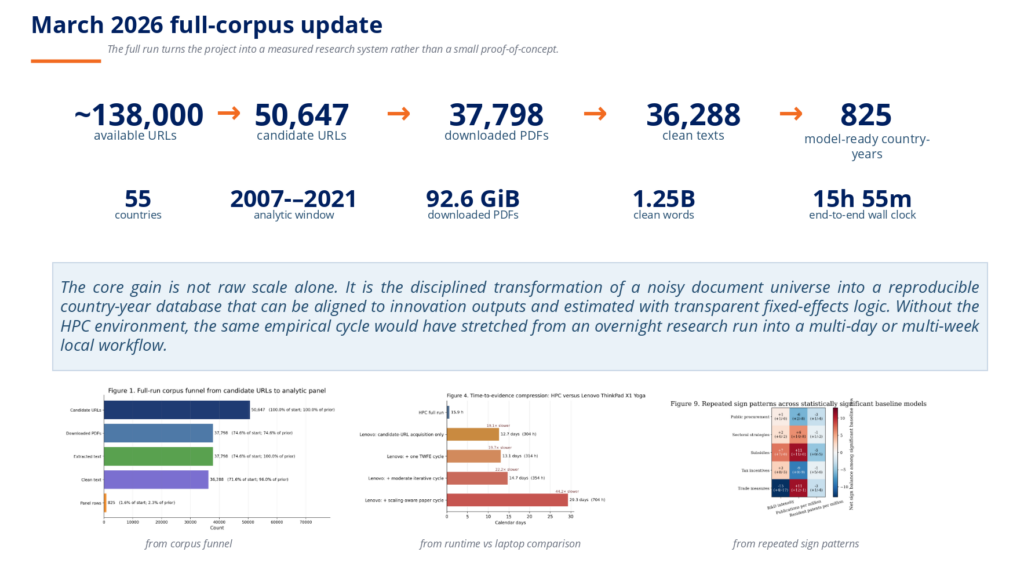
Within the EuroCC initiative, and supported by NCC Montenegro through access to the University of Donja Gorica (UDG) HPC cluster, researchers developed an end-to-end NLP pipeline for large-scale quantitative analysis of industrial policy documents. The project processed over 50,000 raw policy documents, cleaning and structuring more than 36,000 texts into a dataset of 825 country-year observations spanning 55 countries over the period 2007–2021. Using NLP techniques, the pipeline extracted two key policy signals: policy attention (the degree to which a topic is discussed) and policy orientation (whether the framing is positive or negative). These signals were then linked to measurable national innovation outcomes such as patent activity, R&D investment, and scientific publications. Thanks to the HPC infrastructure provided by NCC Montenegro, the complete analytical pipeline was executed in approximately 16 hours — a task that would have taken several weeks on a standard computer.
BENEFITS
- Dramatic time savings enabled by HPC: The full analytical pipeline — processing tens of thousands of documents across 55 countries — was completed in ~16 hours on the UDG HPC cluster, compared to an estimated several weeks on conventional hardware, enabling rapid iteration and model refinement.
- New quantitative tools for policy analysis: The project transformed unstructured policy text into a structured, comparable dataset of 825 country-year observations, providing researchers and policymakers with measurable indicators derived directly from policy documents.
- Evidence-based policy insights: Results revealed that industrial policy does not have a uniform effect on innovation — its impact depends on both the policy type and how it is communicated, with scientific publications responding faster than patents or R&D investment.
- Early warning signals for innovation monitoring: Text-based policy signals extracted through NLP can serve as leading indicators of shifts in national innovation environments, offering a new tool for monitoring policy effectiveness in near real time.
- Broader impact for academia and public sector: The methodology demonstrates how HPC and AI-driven text analysis can be applied to transform policy documents into a strategic data source for researchers, government institutions, and firms tracking innovation ecosystems.
NCC Montenegro provided HPC infrastructure access and technical support under the EuroCC initiative, enabling this research to scale from a proof-of-concept to a full cross-national study.