
Analiza teksta industrijske politike u velikom obimu
PROBLEM / IZAZOV
Savremene industrijske i inovacione politike sve su više ugrađene u ogromne količine strateških dokumenata, nacionalnih izvještaja i policy papira. Iako ovi dokumenti sadrže dragocjene informacije o prioritetima i smjernicama vlada, tradicionalno su tretirani kao narativni tekstovi, a ne kao kvantitativni izvori podataka. Njihova ručna analiza u desetinama zemalja i kroz više godina jednostavno nije izvodiva — razmjere zadatka prevazilaze ono što bi bilo koji istraživački tim mogao ostvariti uz standardne računarske resurse. Istraživači se suočavaju s temeljnim uskim grlom: postoje hiljade policy dokumenata, ali ne postoji efikasna i ponovljiva metoda za izvlačenje uporedivih, strukturiranih signala iz njih na međunarodnom nivou.
Izazov je bio dodatno uvećan potrebom za metodološkom rigoroznošću. Izdvajanje smislenih policy signala — poput toga koliko se pažnje posvećuje određenoj temi ili da li je ta tema okvirena pozitivno ili negativno — zahtijeva primjenu pipeline-a za obradu prirodnog jezika (NLP) na desетke hiljada dokumenata istovremeno. Na standardnom laptopu ili radnoj stanici, pokretanje ovakvog kompletnog analitičkog procesa trajalo bi nekoliko sedmica, što iterativni razvoj modela i poređenje na nivou više zemalja čini praktično nemogućim.

RJEŠENJE
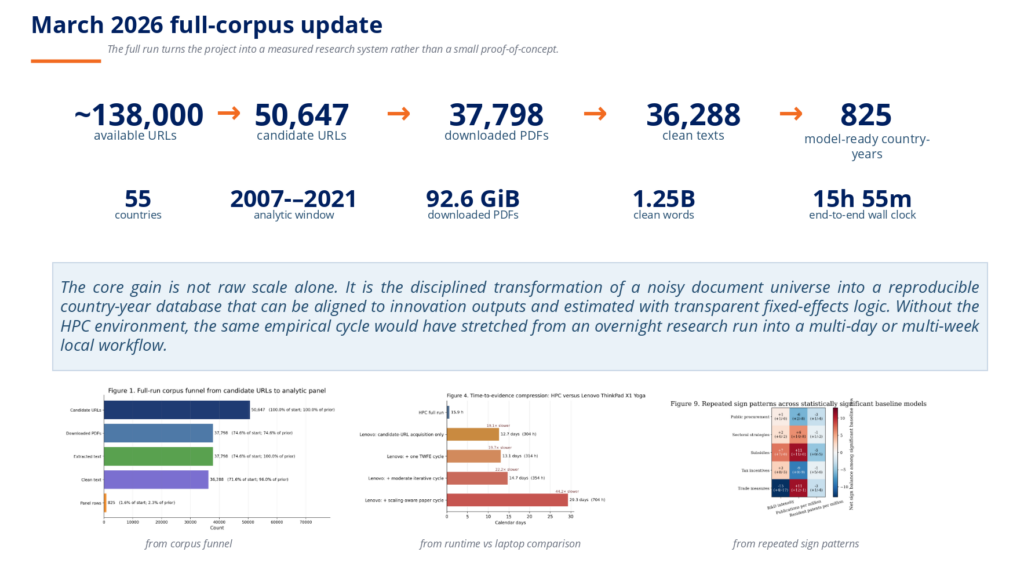
U okviru inicijative EuroCC, uz podršku NCC Crna Gora kroz pristup HPC klasteru Univerziteta Donja Gorica (UDG), istraživači su razvili cjeloviti NLP pipeline za kvantitatvnu analizu policy dokumenata industrijske politike u velikom obimu. U okviru projekta obrađeno je više od 50.000 sirovih policy dokumenata, od kojih je više od 36.000 tekstova očišćeno i strukturirano u skup podataka od 825 opservacija po zemlji i godini, obuhvatajući 55 zemalja u periodu od 2007. do 2021. godine. Uz pomoć NLP tehnika, pipeline je izvukao dva ključna policy signala: pažnju politike (u kojoj mjeri se određena tema razmatra) i orijentaciju politike (da li je narativ pozitivan ili negativan). Ovi signali su zatim povezani s mjerljivim nacionalnim inovacionim ishodima, kao što su patentna aktivnost, ulaganje u istraživanje i razvoj te naučne publikacije. Zahvaljujući HPC infrastrukturi NCC Crna Gora, kompletan analitički pipeline izvršen je za otprilike 16 sati — zadatak koji bi na standardnom računaru trajao nekoliko sedmica.
BENEFITI
- Drastična ušteda vremena zahvaljujući HPC-u: Kompletan analitički pipeline — obrada desetina hiljada dokumenata u 55 zemalja — završen je za ~16 sati na UDG HPC klasteru, nasuprot procijenjenim nekoliko sedmica na konvencionalnom hardveru, što je omogućilo brzu iteraciju i usavršavanje modela.
- Novi kvantitativni alati za analizu politike: Projekat je pretvorio nestrukturirani policy tekst u strukturirani, upоredivi skup podataka od 825 opservacija po zemlji i godini, pružajući istraživačima i kreatorima politika mjerljive pokazatelje direktno izvedene iz policy dokumenata.
- Empirijski utemeljeni zaključci o politici: Rezultati su pokazali da industrijska politika nema jednoobrazni efekat na inovacije — njen uticaj zavisi i od vrste politike i od načina na koji se komunicira, pri čemu naučne publikacije reaguju brže od patenata ili ulaganja u istraživanje i razvoj.
- Rani signali za praćenje inovacionih sistema: Policy signali zasnovani na tekstu, izvučeni putem NLP-a, mogu služiti kao vodeći indikatori promjena u nacionalnim inovacionim okruženjima, nudeći novi alat za praćenje efektivnosti politike gotovo u realnom vremenu.
- Širi uticaj za akademiju i javni sektor: Metodologija demonstrira kako HPC i analiza teksta zasnovana na vještačkoj inteligenciji mogu transformisati policy dokumente u strateški izvor podataka za istraživače, državne institucije i kompanije koje prate inovacione ekosisteme.
NCC Crna Gora je obezbijedilo pristup HPC infrastrukturi i tehničku podršku u okviru inicijative EuroCC, omogućavajući ovom istraživanju da preraste iz proof-of-concept studije u potpunu međunarodnu analizu.