
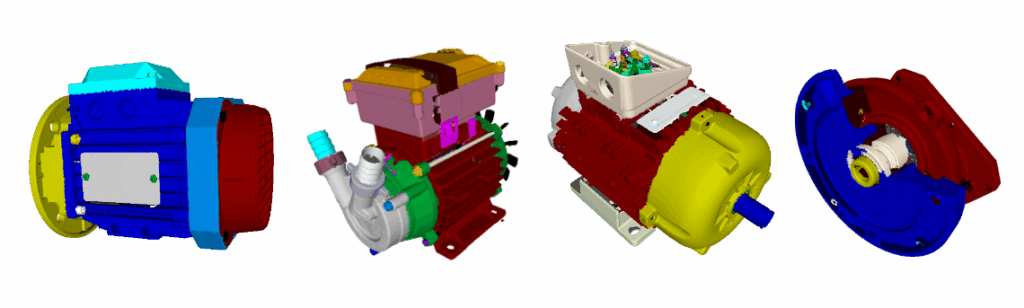
PROBLEM/CHALLENGE
The recognition of shapes from partial 3D scans is a research objective shared by computer graphics and computer vision. At the core of these research challenges lies the need to attach semantic meaning to 3D shape representations, and to do so on a large scale. Segmentation of 3D representations of mechanical assemblies has numerous industrial applications, particularly in scenarios where knowledge about individual mechanical parts and their spatial relationships is beneficial. This includes quality control, reverse engineering, digital twin creation, augmenting CAD models with metadata extracted from segmented scans, operator training for assembly and disassembly, and generating digital instruction sheets using augmented reality.
However, segmentation of mechanical assemblies presents numerous challenges. The diversity of mechanical parts reduces generalization ability, as many components are custom-designed and unseen in training datasets. Moving parts complicate matters by appearing in different relative positions depending on the configuration, while non-rigid elements such as cables or pipes add further variability. Additionally, mechanical assemblies often feature densely packed components with minimal or poorly visible boundaries, making it difficult to separate parts. Even the definition of what constitutes “a part” can be context-dependent. This variability complicates both ground-truth creation and model evaluation, not to mention the complexity of model designing and training.
The ultimate goal of this research is the segmentation of mechanical assemblies such as electric motors, pumps, and gearboxes, while also ensuring that models can generalise to unseen types of assemblies.
SOLUTION
Through a joint effort with the industrial partner Cetim (France) and the academic partner IMT Mines Albi (France), we managed to create a model that achieves high performance in the segmentation of complex mechanical assemblies from 3D scans, demonstrating both the scientific and industrial impact of this approach.
Due to the complexity of defining fixed rules for identifying mechanical parts across different assemblies, rule-based methods are insufficient. Deep learning techniques were therefore chosen for the segmentation of 3D point clouds. However, such models require large volumes of annotated data to perform effectively. To address this, synthetic training data was generated using the publicly available ABC dataset, which contains more than one million industrial CAD models. Originally intended for tasks such as normal prediction and curvature estimation, the dataset proved highly valuable for segmentation. CAD model trees were parsed to extract building blocks, which were treated as individual mechanical parts. Instances were manually verified to avoid over- or under-segmentation errors. To approximate real scanning conditions, a simulated process was applied, keeping only the externally visible components of assemblies. This provided training data closely aligned with what would be captured by real 3D scanners. Finally, a transformer-based deep learning instance segmentation model was pretrained on large amounts of synthetic data and then finetuned on a smaller set of real 3D scans. To achieve best results, we additionally incorporated features extracted from 2D renders of mechanical assembly. This two-step training strategy significantly improved model performance, balancing large-scale synthetic training with real-world adaptation.
BENEFITS
The integration of deep learning, synthetic data generation, HPC, and 3D scanning has brought multiple benefits:
- Improved detection accuracy of individual mechanical parts, even in densely packed assemblies.
- Generalization to unseen assemblies, enabling broader applicability in industrial settings.
- Substantial reduction of manual segmentation effort, saving engineers time in reverse engineering and inspection.
- Provided support for downstream applications, including digital twin creation, operator training, and automated disassembly planning.
- Scalable and efficient workflows, supported by synthetic datasets, HPC resources, and pretraining, making the approach adaptable to real-world industrial requirements.
- Feasibility of experiments within practical timeframes, as HPC provided the computational power needed to train and evaluate models on large datasets without singinfficant delays.