
Problem / Challenge
In the age of large language models, smaller languages like Montenegrin risk being left behind. Most advanced AI language systems are trained on massive English-language datasets, while Montenegrin has very limited digital resources. A large portion of its literature still exists only in printed form, and there are almost no sizeable, well-structured parallel corpora for training or adapting modern AI models. This “digital divide” threatens to exclude Montenegrin speakers from high-quality translation, search, chatbots, and other language technologies that are becoming standard in larger markets.
For his Master’s thesis at the University of Donja Gorica, Igor Ćulafić set out to change this situation by creating an end-to-end pipeline that transforms physical Montenegrin books into high-quality training data and then uses high-performance computing (HPC) to adapt state-of-the-art large language models. The core challenge was twofold: digitise thousands of books efficiently and reliably, and then leverage HPC and AI to build and evaluate language models that genuinely understand Montenegrin and can support real-world, industry-relevant applications.
Solution
The project combined custom hardware, computer vision, and HPC-powered AI training into a single integrated pipeline. It started with hardware: a specialised, V-shaped book scanner, designed and built from scratch, capable of non-destructive, high-throughput digitisation of books. The scanner uses a 120-degree cradle to protect bindings, optimised LED lighting to avoid reflections, and modular 3D-printed components to accommodate different book sizes. Using this system, 5,000 Montenegrin books from the public domain and 40,000 English books from Project Gutenberg were digitised.
Next, a computer vision and OCR pipeline transformed raw images into clean, usable text. YOLO v11 models automatically detected and cropped individual pages, while a customised Tesseract OCR setup handled both Latin and Cyrillic scripts. Additional algorithms corrected perspective distortions and lighting variations to maximise text quality. On top of this, AI-assisted matching created 46,661 high-quality parallel paragraph pairs by aligning Montenegrin and English versions of 2,865 books—an invaluable resource for translation and cross-lingual training.
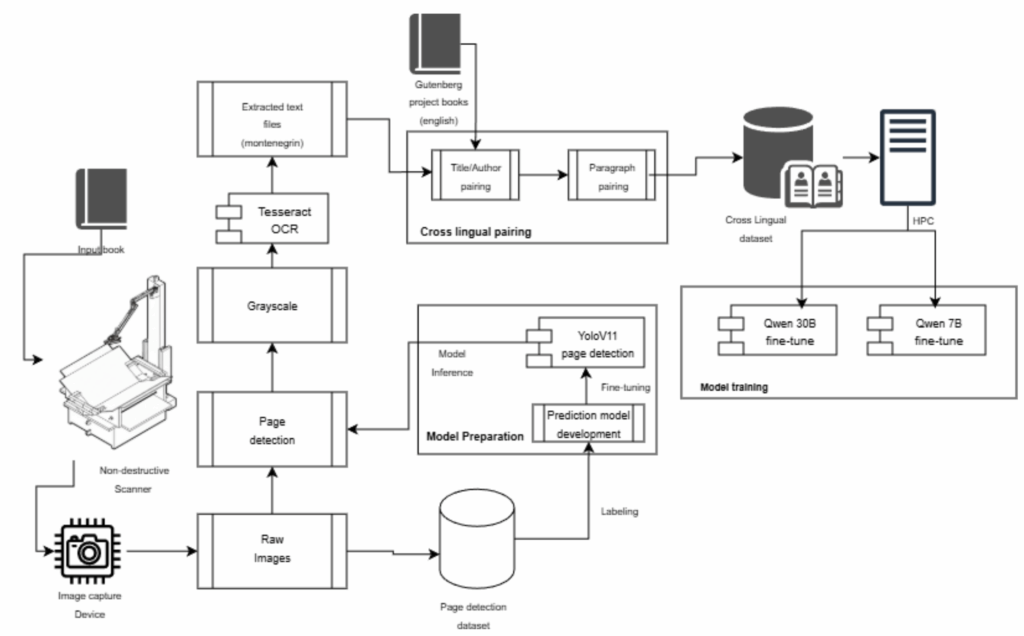
The final stage took place on CINECA’s Leonardo EuroHPC supercomputer, accessed with support from NCC Montenegro through the EuroCC2 and EUROCC4SEE projects. Using NVIDIA A100 GPUs and 144,000 core hours, the team fine-tuned two state-of-the-art open models—Qwen2.5-7B and Qwen3-30B—on the newly created Montenegrin–English corpus, applying parameter-efficient LoRA techniques. This allowed experimentation with models large enough to capture complex linguistic and cultural nuances, yet efficient enough to train within realistic academic compute budgets.
A custom benchmark of ten progressively more difficult tasks (grammar, vocabulary, cultural knowledge, formal writing, technical translation, and analytical reasoning in Montenegrin) was designed to evaluate progress. Results showed clear improvements in grammatical accuracy, terminology consistency, and handling of Montenegrin cultural context, while also surfacing remaining issues such as occasional mixing of Latin and Cyrillic scripts and hallucinated symbols—valuable feedback for future research and dataset expansion.

Throughout the project, NCC Montenegro provided guidance on HPC resource access, efficient job configuration, monitoring and optimisation of GPU usage, and good practices for reproducible AI workflows on supercomputers, turning a single thesis into a blueprint for future HPC-enabled language AI projects in the region.
Benefits
- Demonstrates that cutting-edge large language models for Montenegrin can be built and improved using EuroHPC resources and parameter-efficient fine-tuning.
- Provides a documented workflow from physical books to aligned training data and fine-tuned LLMs, using accessible hardware (3D printing, commodity cameras) and open-source software components.
- Creates tens of thousands of parallel paragraph pairs in Montenegrin–English, a foundation for future translation services, cross-lingual search, and domain-specific assistants.
- Strengthens national expertise in HPC and AI by training a new generation of researchers to use supercomputers like Leonardo, in line with the mission of EuroCC2 and EUROCC4SEE.
- Opens the way for Montenegrin-capable chatbots, virtual assistants, and translation engines for government services, media, banking, tourism, and customer support—reducing reliance on English-only tools.
- Offers a template that can be adapted by other Western Balkan and European languages facing similar data and compute constraints.
- Identifies current limitations (script mixing, limited domain diversity) and highlights the need for more varied data sources (news, online content, conversational speech), guiding follow-up projects and collaborations between academia, NCC Montenegro, and industry partners.