
Problem / Izazov
U doba velikih jezičkih modela, manji jezici poput crnogorskog riskiraju da zaostanu. Većina naprednih jezičkih sistema vještačke inteligencije obučava se na ogromnim skupovima podataka na engleskom jeziku, dok crnogorski jezik ima vrlo ograničene digitalne resurse. Veliki dio njegove literature još uvijek postoji samo u štampanom obliku, a gotovo da nema značajnih, dobro strukturiranih paralelnih korpusa za obuku ili prilagođavanje modernih modela vještačke inteligencije. Ovaj „digitalni jaz“ prijeti da isključi govornike crnogorskog jezika iz visokokvalitetnih prevodilačkih, pretraživačkih, chatbotova i drugih jezičkih tehnologija koje postaju standardne na većim tržištima.
Za svoju magistarsku tezu na Univerzitetu Donja Gorica, Igor Ćulafić je krenuo u promjenu ove situacije stvaranjem cjevovoda od početka do kraja koji transformiše fizičke crnogorske knjige u visokokvalitetne podatke za obuku, a zatim koristi računarstvo visokih performansi (HPC) za prilagođavanje najsavremenijih velikih jezičkih modela. Osnovni izazov bio je dvostruk: efikasno i pouzdano digitalizirati hiljade knjiga, a zatim iskoristiti HPC i umjetnu inteligenciju za izgradnju i evaluaciju jezičkih modela koji istinski razumiju crnogorski jezik i mogu podržati stvarne, industrijske aplikacije.
Rješenje
Projekat je kombinovao prilagođeni hardver, računarski vid i HPC-om pokretanu umjetnu inteligenciju obuku u jedan integrirani proces. Počelo je s hardverom: specijaliziranim skenerom knjiga u obliku slova V, dizajniranim i izgrađenim od nule, sposobnim za nerazornu, visokopropusnu digitalizaciju knjiga. Skener koristi kolijevku od 120 stepeni za zaštitu poveza, optimizirano LED osvjetljenje kako bi se izbjegle refleksije i modularne 3D printane komponente kako bi se prilagodile različitim veličinama knjiga. Koristeći ovaj sistem, digitalizirano je 5.000 crnogorskih knjiga iz javnog domena i 40.000 engleskih knjiga iz Projekta Gutenberg.
Zatim su procesi računarskog vida i OCR-a transformirali sirove slike u čist, upotrebljiv tekst. YOLO v11 modeli su automatski detektovali i izrezivali pojedinačne stranice, dok je prilagođena Tesseract OCR postavka obrađivala i latinična i ćirilična pisma. Dodatni algoritmi su ispravljali distorzije perspektive i varijacije osvjetljenja kako bi se maksimizirao kvalitet teksta. Pored toga, usklađivanje uz pomoć vještačke inteligencije kreiralo je 46.661 visokokvalitetnih paralelnih paragrafa poravnavanjem crnogorskih i engleskih verzija 2.865 knjiga – neprocjenjiv resurs za prevođenje i međujezičnu obuku.
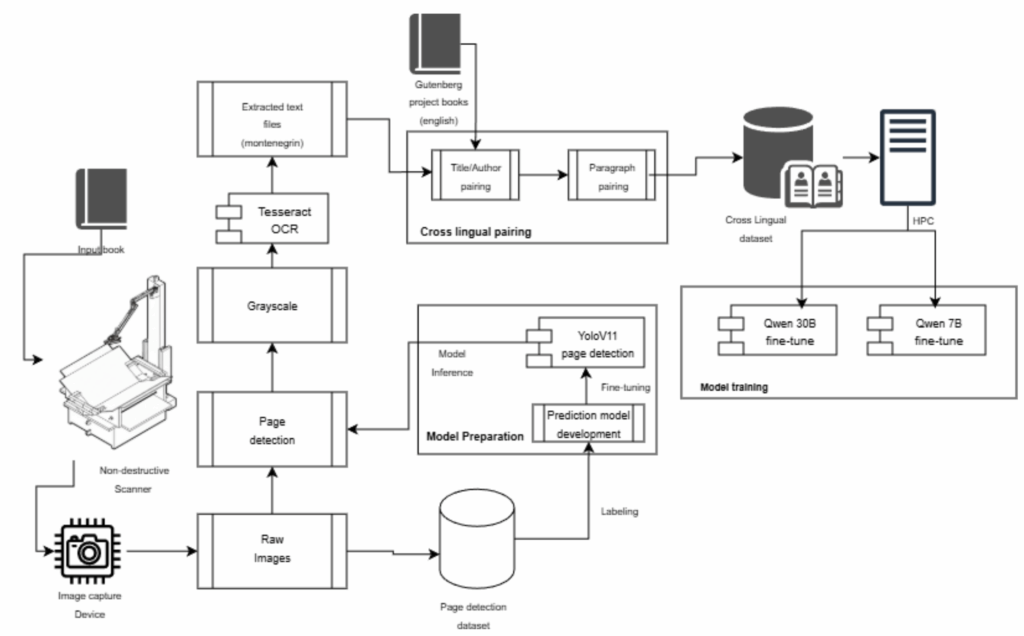
Završna faza se odvijala na CINECA-inom superračunaru Leonardo EuroHPC, kojem je pristupljeno uz podršku NCC Montenegro kroz projekte EuroCC2 i EUROCC4SEE. Koristeći NVIDIA A100 GPU-ove i 144.000 sati rada jezgre, tim je fino podesio dva najsavremenija otvorena modela – Qwen2.5-7B i Qwen3-30B – na novokreiranom crnogorsko-engleskom korpusu, primjenjujući LoRA tehnike koje efikasne u pogledu parametara. Ovo je omogućilo eksperimentisanje s modelima dovoljno velikim da uhvate složene jezičke i kulturne nijanse, a opet dovoljno efikasnim za obuku unutar realnih akademskih računarskih budžeta.
Prilagođeni benchmark od deset progresivno težih zadataka (gramatika, vokabular, kulturno znanje, formalno pisanje, tehnički prijevod i analitičko razmišljanje na crnom jeziku) dizajniran je za procjenu napretka. Rezultati su pokazali jasna poboljšanja u gramatičkoj tačnosti, konzistentnosti terminologije i rukovanju crnogorskim kulturnim kontekstom, a istovremeno su iznijeli na površinu preostale probleme poput povremenog miješanja latiničnog i ćiriličnog pisma i haluciniranih simbola – vrijedne povratne informacije za buduća istraživanja i proširenje skupa podataka.

Tokom projekta, NCC Montenegro je pružao smjernice o pristupu HPC resursima, efikasnoj konfiguraciji poslova, praćenju i optimizaciji korištenja GPU-a, te dobre prakse za reproducibilne AI tokove rada na superračunarima, pretvarajući jednu tezu u nacrt za buduće HPC-omogućene AI projekte jezika u regiji.
Benefiti
- Pokazuje da se vrhunski modeli velikih jezika za crnogorski jezik mogu izgraditi i poboljšati korištenjem EuroHPC resursa i parametarski efikasnog finog podešavanja.
- Pruža dokumentovani tok rada od fizičkih knjiga do usklađenih podataka za obuku i fino podešenih LLM-ova, koristeći dostupan hardver (3D štampanje, standardne kamere) i softverske komponente otvorenog koda.
- Kreira desetine hiljada paralelnih parova paragrafa na crnogorsko-engleskom jeziku, osnovu za buduće prevodilačke usluge, međujezičnu pretragu i asistente specifične za domen.
- Jača nacionalnu stručnost u HPC-u i AI obučavanjem nove generacije istraživača za korištenje superračunara poput Leonardo, u skladu s misijom EuroCC2 i EUROCC4SEE.
- Otvara put za chatbotove, virtuelne asistente i prevodilačke mehanizme sposobne za crnogorski jezik za vladine usluge, medije, bankarstvo, turizam i korisničku podršku – smanjujući oslanjanje na alate samo na engleskom jeziku.
- Nudi predložak koji mogu prilagoditi drugi jezici Zapadnog Balkana i Evrope koji se suočavaju sa sličnim ograničenjima podataka i računarstva.
- Identifikuje trenutna ograničenja (miješanje pisama, ograničena raznolikost domena) i ističe potrebu za raznovrsnijim izvorima podataka (vijesti, online sadržaj, konverzacijski govor), usmjeravajući daljnje projekte i saradnju između akademske zajednice, NCC Montenegro i industrijskih partnera.